3D Gaussian Splatting for Real-Time Radiance Field Rendering
用于实时辐射场渲染的三维高斯泼溅
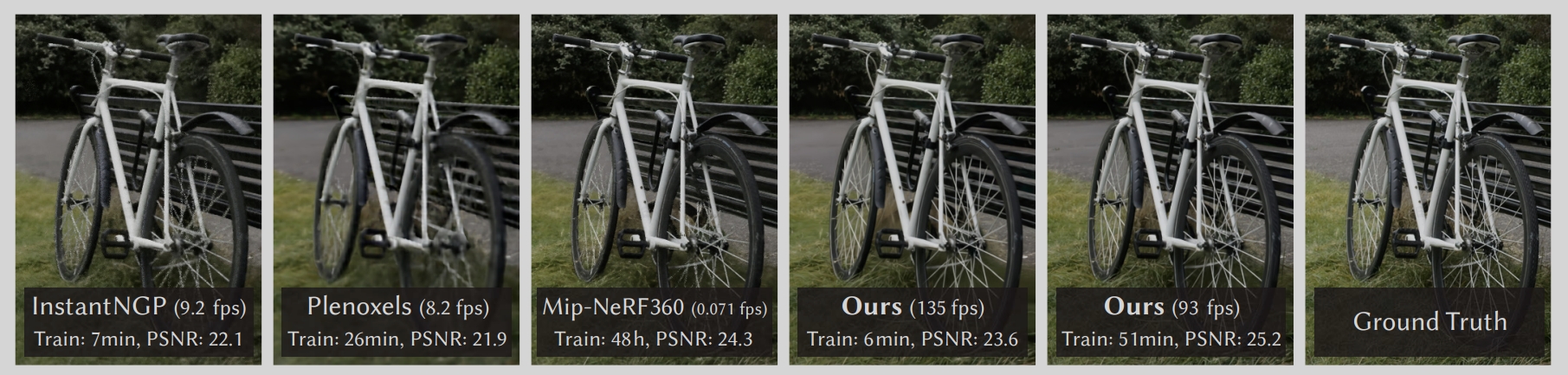

研究背景
关键贡献
- 3D高斯分布表示
- 优化与密度控制
- 基于瓦片的GPU高速渲染
方法总览
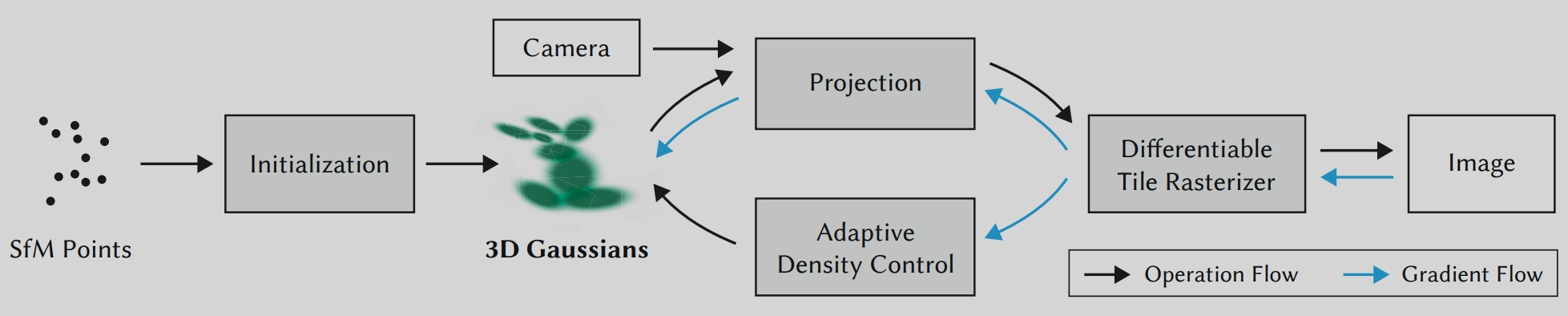
使用SFM算法从静态场景的多视角图像得到稀疏点云
以稀疏点云为基础,为每个点创建3D高斯,定义核心属性
- 位置(均值μ):使用SFM点坐标
- 协方差矩阵(Σ):初始设为各向同性(轴长=到最近3个点的平均距离)
- 不透明度(α):初始值通过梯度友好的SIGMOID函数约束在[0,1)
- 颜色标识:采用球谐函数(SH)编码,初始仅优化0阶分量
给定一个相机视角:将3DGS投影到2D图像空间
使用瓦片式可微光栅化器,基于当前的3D高斯集合渲染出该相机视角下的场景图像
对比“渲染图”与“该视角下的真实图”,使用损失函数计算误差
反向传播更新3DGS的关键参数
自适应密度控制
技术细节
3DGS的数学表示
$ G(x)=e^{-\frac{1}{2}(x)^{T}\Sigma^{-1}(x)} $
协方差矩阵的分解优化
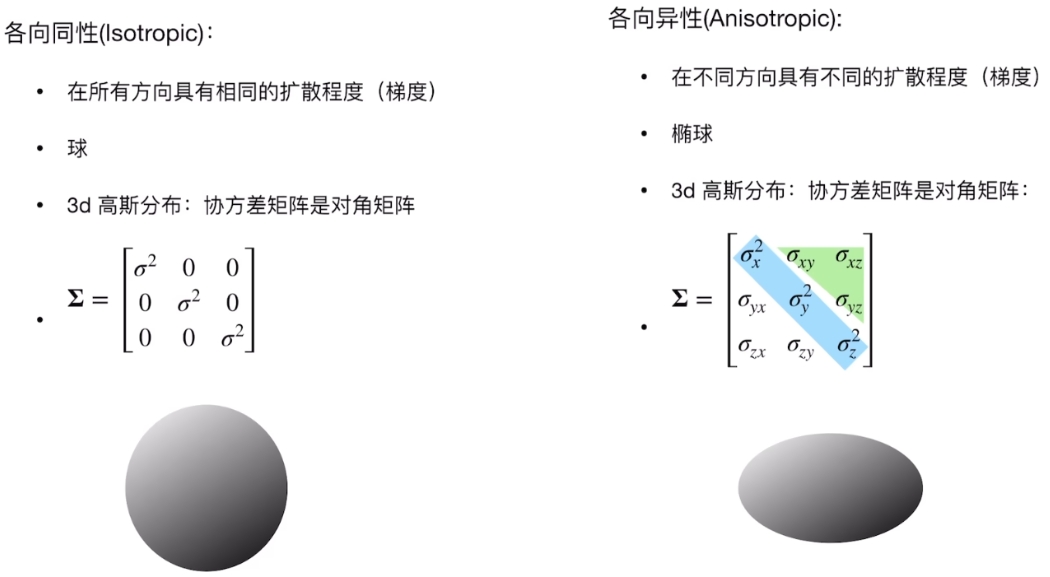
从仿射变换理解高斯分布
任意3D高斯可以看作标准高斯通过仿射变换得到的:
标准高斯(球形,各向同性):
$$G_0(\mathbf{x}) = \exp\left(-\frac{1}{2}\mathbf{x}^T \Sigma_0 \mathbf{x}\right)$$协方差矩阵为单位矩阵 $\Sigma_0 = I$,在3D空间中是一个标准球体。
仿射变换将标准球体变换为任意椭球:
$$\mathbf{y} = \mathbf{A}\mathbf{x} + \mu$$其中:
- $\mathbf{A}$:线性变换矩阵(拉伸+旋转)
- $\mu$:平移向量(高斯中心位置)
变换后的协方差矩阵变为:
$$\Sigma = \mathbf{A} \mathbf{I} \mathbf{A}^T$$分解为旋转和缩放
将线性变换矩阵 $\mathbf{A}$ 分解为缩放和旋转的组合:
$\mathbf{A} = \mathbf{R}\mathbf{S}$
其中:
- S:缩放矩阵,$\mathbf{S} = \text{diag}(s_x, s_y, s_z)$,将球体沿三个轴拉伸
- R:旋转矩阵,$\mathbf{R} \in SO(3)$,改变椭球的朝向
代入协方差矩阵公式:
$$\Sigma = \mathbf{A}\mathbf{A}^T = (\mathbf{R}\mathbf{S})(\mathbf{R}\mathbf{S})^T = \mathbf{R}\mathbf{S}\mathbf{S}^T\mathbf{R}^T$$特征值分解角度
$$ \begin{align} \Sigma &= Q \Lambda Q^T \\ &= Q \Lambda^{1/2} \Lambda^{1/2} Q^T \\ &= (Q \Lambda^{1/2}) (Q \Lambda^{1/2})^T \end{align} $$优化参数
协方差矩阵必须保持正半定性(所有特征值≥0),直接优化9个元素可能导致无效矩阵。
使用分解形式 $\Sigma = \mathbf{R}\mathbf{S}\mathbf{S}^T\mathbf{R}^T$ 的优势:
- 只需优化7个参数(四元数[w,x,y,z]+3个缩放参数[x,y,z])
- 天然保证 Σ 正半定
- 梯度下降不会产生无效矩阵
高斯分布的2D投影
给定一个视角变换矩阵 W(世界坐标→相机坐标),3D高斯投影到2D图像平面的协方差矩阵为:
$$\Sigma' = J W \Sigma W^T J^T$$其中:
- W:视图变换矩阵(旋转+平移)
- J:雅可比矩阵(对线性变换的局部线性近似)
- Σ’:投影后的2D协方差矩阵(2×2)
投影过程:
- 3D高斯中心 μ 投影到屏幕坐标 μ'
- 3D椭球通过仿射近似变换为2D椭圆
- 得到2D高斯参数(μ’, Σ’),用于后续渲染
关键:投影保持了高斯的可微性,允许梯度反传到3D参数
球谐函数表示颜色
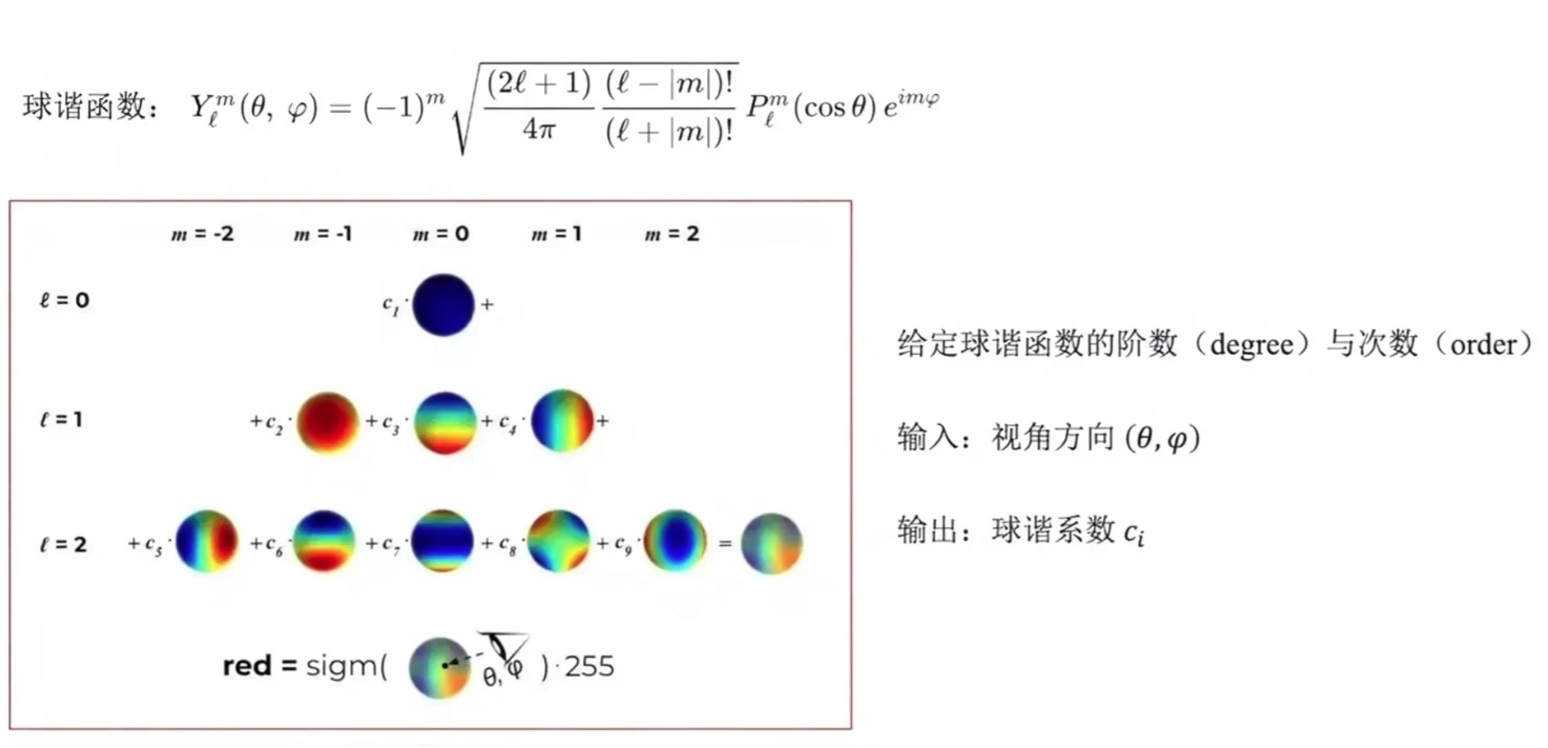
不直接使用RGB的原因:颜色固定,无法很好的处理同一个物体在不同视角下的高光、反射。我们的期望是更好的处理RGB不能解决的问题
α-blending
投影后的2D高斯通过Splatting绘制到图像。对于每个像素,需要混合所有覆盖它的高斯。
像素颜色计算
按深度从前到后排序N个高斯,像素颜色通过Alpha混合累积(论文公式3):
$$C = \sum_{i \in N} c_i \alpha_i \prod_{j=1}^{i-1}(1 - \alpha_j)$$其中:
- $c_i$:第i个高斯的颜色(从球谐函数SH计算,视角相关)
- $\alpha_i$:第i个高斯在该像素的有效不透明度
其中 $o_i \in [0,1]$ 是可学习的不透明度参数,指数项为2D高斯函数(中心为1,边缘趋于0)
- $T_i = \prod_{j=1}^{i-1}(1 - \alpha_j)$:透射率,表示前面所有高斯的累积透光率
物理意义:
- 前景高斯会遮挡后面的高斯
- 半透明高斯允许后面的颜色透过
- 类似传统图形学的Alpha混合
Early Stopping
当透射率接近0时(几乎完全被遮挡),后续高斯的贡献可忽略:
$$T_i = \prod_{j=1}^{i-1}(1 - \alpha_j) < \epsilon$$通常设置 $\epsilon = 0.001$,提前终止可大幅加速渲染(跳过被完全遮挡的高斯)。

优化过程
损失函数
3DGS使用组合损失函数,平衡像素精度和感知质量:
$$\mathcal{L} = (1-\lambda)\mathcal{L}_1 + \lambda \mathcal{L}_{\text{D-SSIM}}$$其中 $\lambda = 0.2$ 是权重系数,控制两种损失的相对重要性。
L1 损失(像素级精度)
$$\mathcal{L}_1 = \frac{1}{HW}\sum_{x,y} |I_{\text{render}}(x,y) - I_{\text{GT}}(x,y)|$$- 计算渲染图像与真实图像每个像素的绝对误差
- 直接优化颜色准确性
- 对离群值鲁棒(相比L2)
D-SSIM 损失(结构相似性)
SSIM(Structural Similarity Index) 是图像质量评价指标,模拟人眼感知(亮度,对比度,纹理结构):
$$\text{SSIM}(x,y) = \frac{(2\mu_x\mu_y + C_1)(2\sigma_{xy} + C_2)}{(\mu_x^2 + \mu_y^2 + C_1)(\sigma_x^2 + \sigma_y^2 + C_2)}$$其中:
- $\mu_x, \mu_y$:图像块的平均亮度(对比亮度)
- $\sigma_x^2, \sigma_y^2$:方差(对比对比度)
- $\sigma_{xy}$:协方差(对比结构相关性)
- $C_1, C_2$:稳定常数(避免除零)
D-SSIM(用于损失函数):
$$\mathcal{L}_{\text{D-SSIM}} = \frac{1-\text{SSIM}}{2}$$将相似性指标转换为损失(SSIM越大越好 → D-SSIM越小越好)
计算过程:
- 在图像上滑动窗口(通常11×11像素)
- 对每个窗口计算局部SSIM值
- 所有窗口的SSIM求平均
- 转换为损失值
SSIM关注三个维度:
- 亮度:整体明暗是否一致
- 对比度:局部明暗变化是否相似
- 结构:纹理模式是否匹配
为什么组合使用?
| 损失类型 | 优点 | 缺点 | 权重 |
|---|---|---|---|
| L1 | 像素精度高,收敛快 | 可能过度平滑,忽略结构 | 80% |
| D-SSIM | 保持边缘锐利,纹理清晰 | 计算复杂,可能颜色漂移 | 20% |
组合效果:
- L1主导优化方向(稳定训练)
- D-SSIM辅助优化细节(提升主观质量)
- 达到客观精度和感知质量的平衡
反向传播梯度
由于渲染过程完全可微:
$$\frac{\partial \mathcal{L}}{\partial \theta} \leftarrow \text{反向传播}$$可直接优化所有参数:
- 3D位置 μ
- 旋转 q
- 缩放 s
- 不透明度 α
- SH系数 k
使用Adam优化器,学习率随训练动态调整。
自适应密度控制
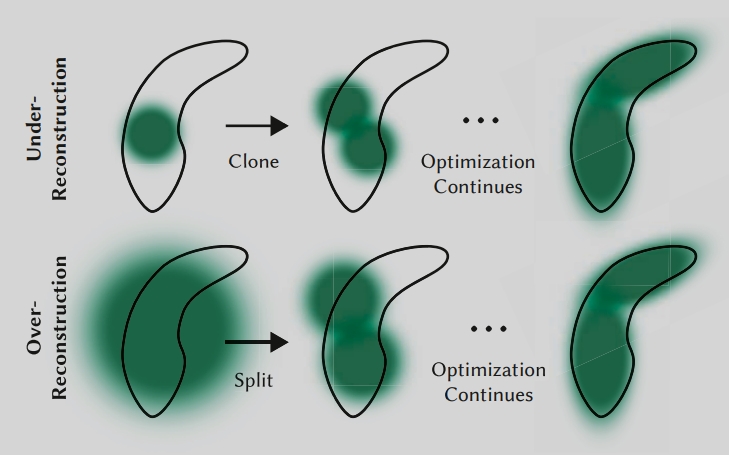
- 删除:定期删除几乎透明的高斯
- 克隆:对重建不足的高斯点进行克隆
- 分裂:对过度重建的高斯点进行分裂
- 定期重置不透明度:防止过渡增长
- 关键参数:分裂缩放因子 $φ=1.6$(经验得到),不透明度阈值$ε_α = 0.005$
快速瓦片渲染
传统Splatting逐高斯渲染效率低,3DGS采用Tile-based Rasterization加速。
示意图
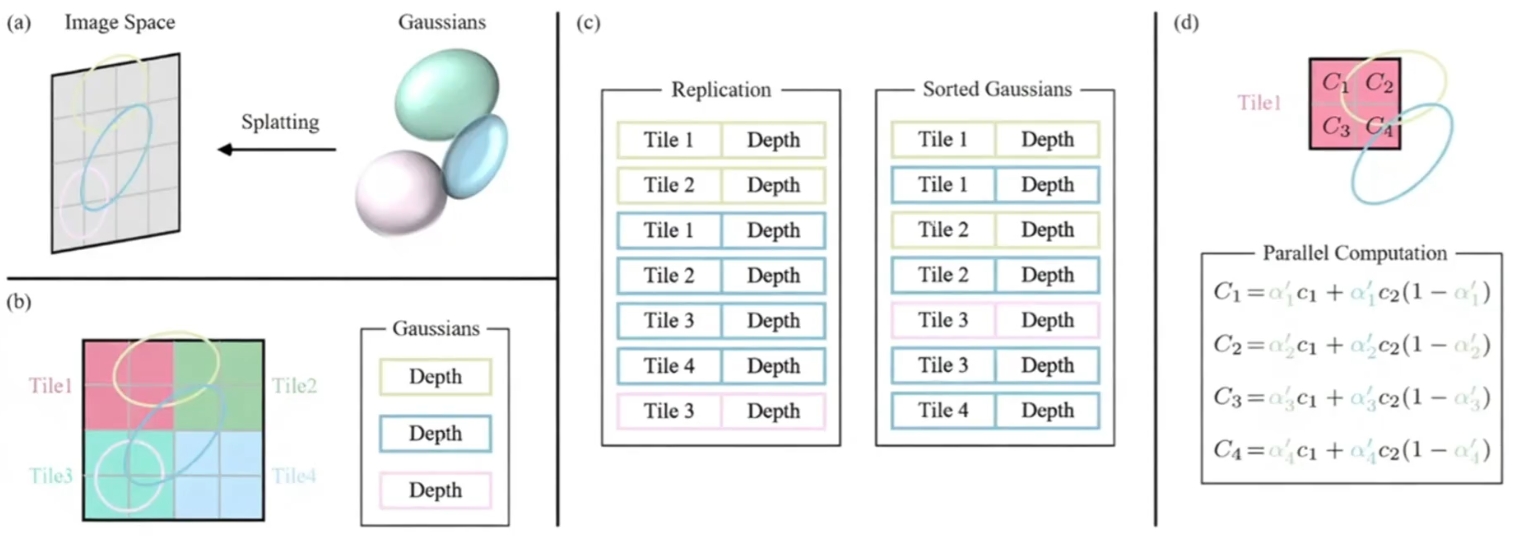
核心思想
| |
| |
渲染流程
投影与剔除:
- 将3D高斯投影到2D
- 剔除视锥外的高斯
Tile分配:
- 计算每个2D高斯的包围盒
- 将高斯ID加入覆盖的tile列表
排序:
- 每个tile内按深度排序高斯(利用GPU排序)
并行渲染:
- 每个tile启动一个线程块
- 独立执行Alpha混合