FastGS: Training 3D Gaussian Splatting in 100 Seconds
目录
Project_Page

核心
提出通用加速框架FastGS, 基于多视角一致性进行3DGS稠密化和剪枝, 在不牺牲渲染质量的前提下, 实现了100秒内训练完成。同时具备很强的泛化性, 适配多种3D重建任务
背景
- 3DGS的自适应密度控制机制存在缺陷, 产生大量冗余高斯体, 增加训练时间和渲染开销
- 对多视图一致性的利用不足
- 渲染管线存在冗余开销
核心
Multi-View Consistent Densification(VCD)
传统的3DGS通过低透明度或规模过大移除冗余, 不能高效解决冗余高斯的问题
核心目的是识别需要细化的局部区域
致密化的核心目标是只在多个视角下都存在渲染误差的区域添加新高斯体. 意思是一个真正对场景重建有价值的高斯体, 应该能改善多个视角下的渲染质量
从全部训练视图中随机选取K个视图(10), 以及真实图像和渲染之后的图像
对于每一个视角, 计算渲染图和真实图在像素的误差:
这里的表示颜色的通道, 公式意思是计算通道的误差的平均值
接下来构造该视图的损失图
表示width, 表示height, 表示对结果进行最小-最大归一化
设置阈值筛选出高误差像素, 也就是渲染质量差的区域, 形成高误差掩码
对于像素来说, 表示渲染质量差
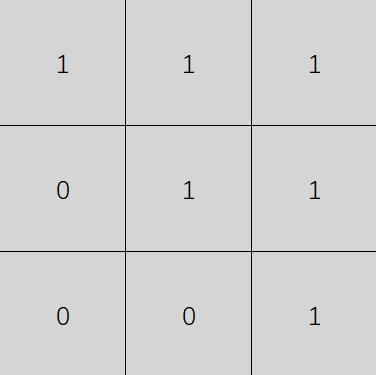
接下来需要找到质量差的像素是由哪些高斯负责的
- 3DGS投影到2D图像平面, 可以得到在该视图下的2D覆盖范围(足迹)
- 统计每个高斯体的2D足迹包含的高误差像素数量, 对应该高斯体对应区域的渲染质量差
对每个高斯体, 将其在K个视图中的高误差像素数量求和后取平均, 得到致密化重要性分数
仅当重要性分数超过阈值时, 才对其进行致密化, 确保新生成的高斯体聚焦于欠重建区域
Multi-View Consistent Pruning(VCP)
剪枝的目的是移除对场景重建贡献小的高斯体, 需要考虑全局重建状态
传统的3DGS通过自身属性(透明度,尺度)或梯度信息来判断是否剪枝, 无法准确区分是真的冗余还是对多视图有用的高斯体, 比如只在少数视角有用, 但整体重要. VCP的核心思想是一个有价值的高斯体, 应该能改善多个视角的渲染质量, 反之, 在多个视角下均对渲染质量无证明贡献, 则可安全剪枝
针对每个视角 , 计算渲染图和真实图之间的损失, 这是因为要判断是否真正影响了 “多视角整体重建质量”, 不是只看覆盖了多少高误差像素
引入初始论文中的整体视角误差:
结合整体视角误差计算贡献度:
Compact Box